

# 뒤에서부터 슬라이싱
06. 다음은 사용자로부터 입력받은 문자열에서 처음과 끝의 3글자를 추출한 후 합쳐서 출력하는 파이썬 코드이다. ⓐ에 들어갈 내용은?
string = input('7문자 이상 입력하시오 :')
m = (ⓐ)
print(m)
입력값: Hello World
최종출력: Helrld
정답 : string[0:3] + stirng[-3:]
- 문자열의 경우 앞 인덱스 0번부터 시작, 뒤에서 인덱스 셀 때는 맨 끝자리가 -1
- 슬라이싱 할 때 [시작점:끝점]에서 끝점은 포함 안하고 끝점-1자리까지 잘라서 반환
- 뒤에서부터 슬라이싱 할 때 [-1:-3] (순방향이라 가능)
- 하지만 [-3:-1] 이런 경우 [] 빈 괄호 출력
- 자르는 방향이 왼쪽에서 오른쪽이면 -1 넣어줘야 함 [-3:-1:-1]
# 인자로 리스트 받을 때
27. 다음 파이썬(Python) 프로그램의 실행 결과는?
def test(x, y=[]):
y.append(x)
return y
print(test(1))
print(test(2))
정답 :
[1]
[1, 2]
틀린 이유 :
매개변수로 들어온 y=[] 빈리스트가 전역 변수처럼 유지되는지 몰랐음
나는 해당 값은 함수 안에서만 사용되고 test(1) 함수가 끝나면 사라지는 지역 변수 개념이라고 생각했음
하지만 인자로 받은 리스트는 재생성되지 않고 함수가 정의될 때 한 번만 생성되고 그 이후에는 값을 재사용
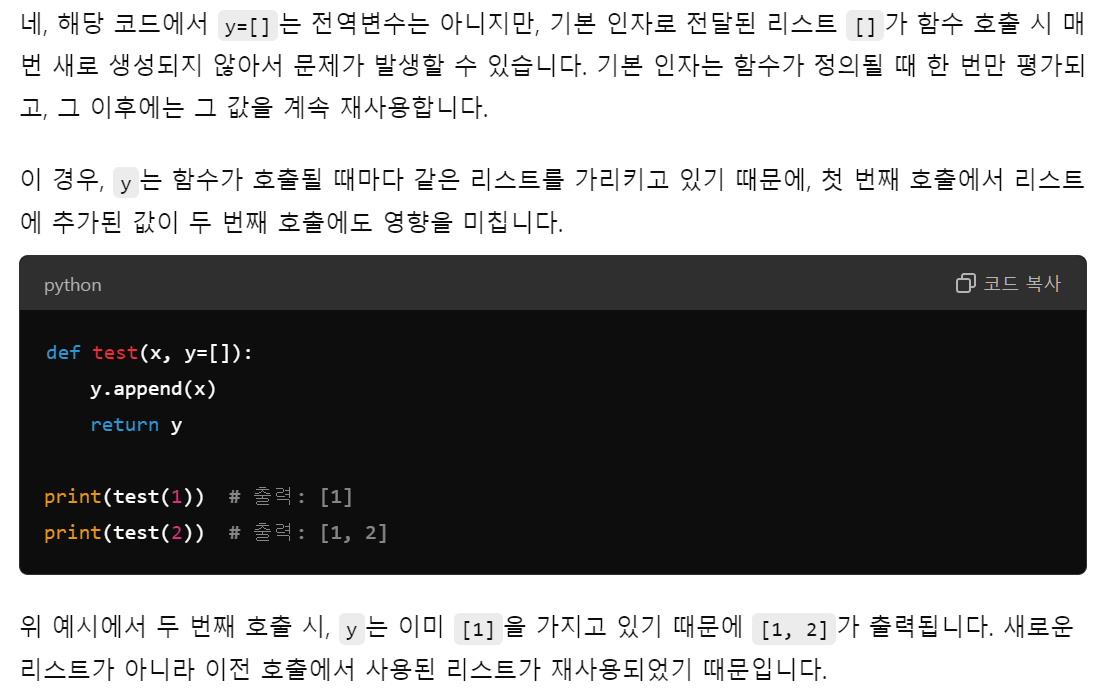
def test(x, y=None):
if y is None:
y = []
y.append(x)
return y
print(test(1)) # 출력: [1]
print(test(2)) # 출력: [2]
이런 동작을 방지하려면, 기본 인자로 None을 사용하고, 함수 내부에서 새로운 리스트를 생성하는 방식으로 수정해야 한다. 위의 코드처럼 작성하면 매번 호출할 때 새로운 리스트가 생성되기 때문에, 각각의 호출이 독립적으로 동작한다.
# 문자열의 인덱스
28. 다음 파이썬(Python) 프로그램의 실행 결과는?
class arr:
a = ['Seoul', 'Keyonggi', 'Inchon', 'Daejoen', 'Daegu', 'Busan']
str = ''
for i in arr.a:
str = str + i[0]
print(str)
정답 : SKIDDB
틀린 이유 : 리스트 값에서 i[0] 이라는게 정확히 무엇을 지칭하는지 몰랐음.
i 가 리스트의 각 요소들인데 파이썬에서는 문자열에도 인덱스가 있음.
즉 각 요소의 첫번째 글자를 말하는 것. 이 경우 리스트의 [ ]없이 글자 하나씩만 추출됨
# 람다(lambda)
✅ Lambda(람다) 란?
파이썬에서 **람다(lambda)**는 간결하게 작성할 수 있는 익명 함수입니다. lambda 키워드를 사용하여 정의되며, 보통 간단한 함수나 일회성 함수가 필요한 곳에서 많이 사용됩니다.
람다 함수의 일반적인 형태:
lambda 인자1, 인자2, ...: 표현식
람다 함수는 보통 한 줄로 작성되고, 여러 줄에 걸친 복잡한 로직은 포함할 수 없습니다. 함수의 본문에는 하나의 표현식만 들어가야 하며, 그 결과가 반환됩니다.
✅ 사용 예시
1. 기본 사용 예시
add = lambda x, y: x + y
print(add(3, 5)) # 출력: 8위의 예시는 x와 y를 더하는 람다 함수로, add라는 변수에 저장되어 나중에 호출할 수 있습니다.
2. 함수의 인자로 사용
람다는 함수를 인자로 전달할 때도 유용하게 쓰입니다.
예를 들어, sorted() 함수에서 정렬 기준을 정의할 때 사용 가능합니다.
# 두 번째 요소를 기준으로 리스트 정렬
pairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
sorted_pairs = sorted(pairs, key=lambda pair: pair[1])
print(sorted_pairs)
# 출력: [(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]
3. map(), filter(), reduce()와 함께 사용
- map() 예시:
numbers = [1, 2, 3, 4]
squared = list(map(lambda x: x ** 2, numbers))
print(squared) # 출력: [1, 4, 9, 16]
- filter() 예시:
numbers = [1, 2, 3, 4]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 출력: [2, 4]
# lambda num: num+100, a
34. 다음 파이썬(Python) 프로그램의 실행 결과는?
a = [1,2,3,4,5]
b = list(map(lambda num:num+100, a))
print(b)
결과값 : [101, 102, 103, 104, 105]
a 라는 컬렉션에 있는 값을 하나씩 뽑아서 앞의 num+100이라는 함수 처리를 하여 리스트 형태로 반환
36. 다음 파이썬(Python) 프로그램의 실행 결과는?
contry = ['Korea', 'Spain', 'Germany', 'Canada', 'france', 'Serbia']
print(max(country))
print(max(country, key=lambda x:x[2]))
print(max(country, key=lambda i:i.lower()))
결과값 :
france
Korea
Spain
아스키 코드로 A=65, a=97 이기 때문에 소문자 f인 france가 가장 높은 값 가짐
두 번째 에서는 리스트의 각 요소를 x라고 명하고 x의 2번째 인덱스 값끼리 비교하는 문제
이 때 중복값이 있으면 첫 번째 나오는 값이 max 값이라고 본다, 즉 Kor 과 Ger 모두 2번 인덱스 값이 r이지만 Korea가 답
마지막은 문자를 모두 소문자로 바꾸고 비교하기. spain 과 serbia 모두 s로 값이 동일하지만 먼저 나온 spain이 답
'정보처리기사' 카테고리의 다른 글
| [Java] 정보처리기사 자바의 상속 & 생성자 (3) | 2024.10.23 |
|---|---|
| [Java] 자바의 예외처리 키워드, 예시, 종류 정리 (1) | 2024.10.18 |
| [Java] 정보처리기사 추상클래스 / 인터페이스 정리 (오류 발생 문제 풀이) (3) | 2024.10.18 |
| [Python] 파이썬 학습노트2 -자료구조(리스트, 튜플, 셋, 딕셔너리) (3) | 2024.10.16 |
| [Python] 파이썬 학습노트 1 - 기본 문법 & 문자열 관련 메서드 (2) | 2024.10.15 |