
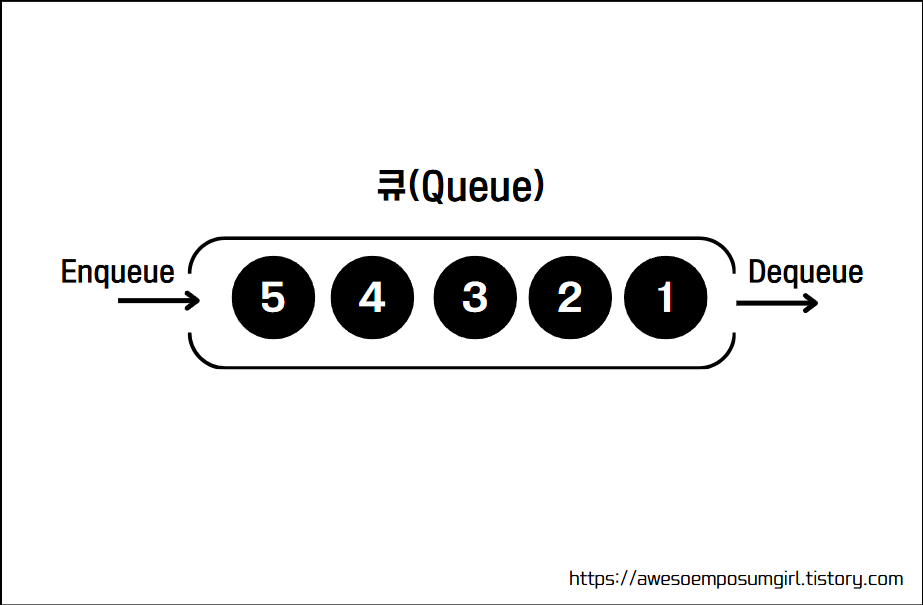
1. 큐(queue)란 무엇인가?
'큐(queue)' 란 '줄을 서다'라는 뜻을 가지고 있다. 큐는 먼저 들어간 데이터가 먼저 나오는 자료구조이며, 이런 큐의 특징을 FIFO(First In First Out) 또는 선입선출이라고 한다. 그리고 큐에서 삽입하는 연산을 Enqueue(add) 라고 하고, 꺼내느 연산을 Dequeue(Poll) 이라고 한다.
2. 큐의 ADT
| 구분 | 정의 | 설명 |
| 연산 | boolean isFull() | 큐에 들어 있는 데이터 개수가 maxsize 인지 확인 해서 boolean 값을 반환 |
| boolean isEmpty() | 큐에 들어 있는 데이터가 하나도 없는지 확인해서 boolean 값을 반환 | |
| void add(ItemType item) | 큐에 데이터 삽입 | |
| ItemType poll() | 큐에서 처음에 삽입한 제이터를 꺼내서 그 데이터를 반환 | |
| 상태 | int front | 큐에서 가장 마지막에 poll 한 위치를 기록 |
| int rear | 큐에서 최근에 add한 데이터의 위치를 기록 | |
| ItemType data[maxsize] | 큐의 데이터를 관리하는 배열 (최대 maxsize개의 데이터를 관리함) |

2-1. 1단계_비어있는 큐에 add() 연산

isFull() 연산으로 현재 큐가 가득 찼는지 확인하고 큐가 가득 차지 않았다면(isFull의 결과가 false) rear에 +1을 한 다음 rear가 가리키는 위치에 3을 add한다. 만약 isFull 연산의 결과값이 true라면 이미 큐가 꽉 찬 상태이기 때문에 데이터를 추가(add)하지 않는다.
2-2. 2단계_배열 기반의 원형 큐 (Circular Queue)에서 poll() 연산

poll()은 큐의 요소를 꺼내는 메서드이다. 위 상태에서 poll()을 호출하기 전에 isEmpty() 연산을 수행하여 큐가 비어 있는지 확인한다. isEmpty()는 front == rear일 때 true를 반환한다. 만약 true라면 큐가 비어 있는 것이므로 poll() 연산을 수행하지 않고 종료된다.
반면, 만약 큐가 비어 있지 않다면 (isEmpty()가 false를 반환할 경우), front 값을 증가시킨다. 원형 큐라면 (front + 1) % capacity 연산을 수행해서 순환구조가 유지된다.
그래서 배열에서 실제 데이터를 지우는 것이 아니라 front 위치만 변경하여 데이터를 삭제한 것처럼 처리한다. 따라서 만약 poll() 후 front == rear이면 큐가 비어 있음을 의미하고 isEmpty() 연산 시 true가 나온다.
원형 큐에서는 front와 rear를 순환 구조로 유지하여 배열을 효율적으로 사용한다. 반면에 원형 큐 (Circular Queue) 가 아닌 일반적인 배열 기반 큐라면, poll() 시마다 front가 증가하면서 배열 공간이 낭비될 수 있다. 이것을 방지하려면 데이터를 앞으로 당기는 추가 작업이 필요하다.
2-3. 3단계_계속해서 add() 하기


계속해서 add 한다. 5를 add하면 isFull() 연산을 수행해서 큐가 가득 찼는지 확인하고, 가득 차지 않으면 숫자를 큐에 추가한다. 6과 8을 add하고 나면 front 는 0 rear는 3이 된다.
2-4. 4단계_큐가 가득 찼을 때 add()하면 어떤 일이 일어날까?
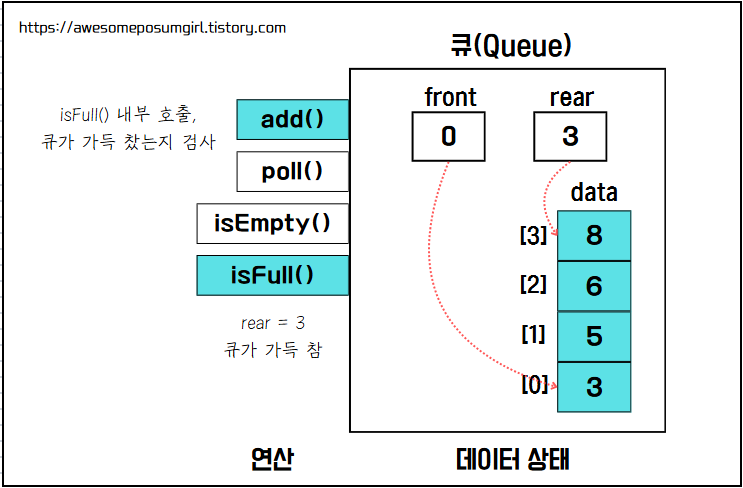
이제 큐가 가득 찼을 때 add하면 어떻게 되는지 살펴 보자. rear가 3이기 때문에 maximize-1과 같다. isFull() 연산은 true이므로 더 이상 add()를 수행하지 못한다.
여기서 생각 해 볼 내용이 하나 있다. 마지막 add에서 실제 data에 저장한 데이터가 3, 5, 6, 8로 4개 이지만 큐는 5, 6, 8로 3개이다. 즉, 큐는 front의 다음부터 rear까지를 큐가 관리하는 데이터로 인식한다. 실제로는 data의 공간이 4개인데 큐가 관리하는 데이터는 3개이므로 실질적으로는 메모리 공간을 낭비한 상황이다. 이렇게 되는 이유는 큐를 한 방향으로 관리하고 있기 때문이다. 이렇게 하면 front 이전의 공간을 활용하지 못 한다. 즉, front 이전을 기준으로 큐가 사용할 수 있는 부분과, 사용할 수 없는 부분으로 나뉘게 된다.
2-5. 큐를 원형으로 만들기

위에서 살펴본 문제점을 개선하기 위해 고안한 다른 형태의 큐가 원형 큐이다. 위에까지의 설명은 선형큐였다. 낭비하는 공간을 없애기 위해 원형으로 큐를 만들고 front와 rear가 돌아간다. 원형 큐는 선형 큐보다 구현이 복잡하지만 메모리 공간을 절약할 수 있다는 장점이 있다. 다만 코딩테스트에서는 자바 컬렉션에서 제공하는 Queue 인터페이스까지만 알아도 충분하다. 왜냐하면 자바의 Queue는 배열의 길이를 자동으로 관리하기 때문이다. 굳이 메모리를 효율적으로 쓰기 위해 원형 큐를 사용할 필요까지는 없고 이런 게 있다 정도로 알아 두면 좋다.
3. 큐를 구현하는 2가지 방식

1. Queue 인터페이스
2. ArrayDeque 덱 클래스
3-1. Queue 인터페이스
Queue<Integer> queue = new ArrayDeque<>();Queue 인터페이스에서는 add 연산을 add()로 메서드로 수행하고 poll 연산은 poll()로 수행한다.
add 연산은 offer() 메서드로도 가능하지만 내부에서 offer() 메서드의 호출 횟수가 1회 더 많기 때문에 add() 메서드를 사용하는 것이 아주 약간의 차이로 빠를 수 있다.
그리고 자바 컬렉션 프레임워크에서 Queue는 인터페이스로 구현되어 있다. Queue의 구현체로 자주 사용하는 클래스는 ArrayDeque와 LinkedList이다. 코테에서는 일반적으로 LinkedList < ArrayDeque이다.
3-2. 덱을 큐처럼 활용하는 방법
ArrayQueue<Integer> queue = new ArrayDeque<>();덱은 Double Ended Queue의 줄임말이다. 말 그대로 양 끝에서 삽입이나 삭제를 할 수 있는 큐를 구현한 것이다. 하지만 ArrayDeque에서는 add()와 poll()보다 addLast()메서드와 pollFirst() 메서드를 대신 사용하는 것이 좋다.

위 그림에서 큐를 기준으로 왼쪽이 First, 오른쪽은 Last이다. 데이터를 왼쪽에서 꺼내는 걸 pollFirst(), 오른쪽으로 넣는 것은 addLast()이다. 추가로, 만약에 데이터를 addFirst()로만 넣고 pollFirst()로만 꺼내면 동작이 stack의 push(), pop()과 동일해서 ArrayDeque로 큐, 스택, 덱 모두 수현이 가능하다.

4. 큐의 상속관계



내가 만든 자료 외 사진 자료 출처
Deque, LinkedList 와 ArrayDeque
이번 시간에는 Deque 인터페이스를 알아보고 이의 구현체인 LinkedList와 ArrayDeque를 알아보고 비교할 것이다. 1. Deque란? 원소의 추가와 삭제를 둘 다 끝부분에서 지원하는 선형 collection. Deque라는 이
tech-monster.tistory.com
Java: 덱(Deque)의 개념과 사용
덱 Double-Ended Queue 큐의 양쪽에 데이터를 넣고 뺄 수 있는 자료구조 큐 또는 스택으로도 사용할 수 있다 덱의 분류 한 쪽으로만 입력이 가능한 덱 = Scroll 한쪽으로만 출력이 가능한 덱 = Shelf 덱은
devyoseph.tistory.com
'코딩테스트 > 알고리즘' 카테고리의 다른 글
| [코딩테스트/알고리즘 맛집] 자바 스택(Stack) 문제 유형과 코드 정리 (12) | 2025.02.19 |
|---|---|
| [알고리즘] 코딩테스트 코드 구현 노하우 - 해시맵, StringBuffer, 조기반환, 보호구문, 제네릭기법 (7) | 2025.02.16 |
| [알고리즘] 그림과 문제로 알아보는 이진트리 탐색 (이분 탐색, Binary Search) (12) | 2025.02.15 |
| [코딩테스트/알고리즘 맛집] 자바 정렬(Sort) 코딩테스트에서 자주 나오는 문제 유형과 풀이 팁 (30) | 2025.02.08 |
| [코딩테스트/알고리즘 맛집] 그리디 알고리즘 (Greedy Algorithm) 으로 빠르고 효율적으로! (18) | 2025.02.05 |
1. 큐(queue)란 무엇인가?
'큐(queue)' 란 '줄을 서다'라는 뜻을 가지고 있다. 큐는 먼저 들어간 데이터가 먼저 나오는 자료구조이며, 이런 큐의 특징을 FIFO(First In First Out) 또는 선입선출이라고 한다. 그리고 큐에서 삽입하는 연산을 Enqueue(add) 라고 하고, 꺼내느 연산을 Dequeue(Poll) 이라고 한다.
2. 큐의 ADT
| 구분 | 정의 | 설명 |
| 연산 | boolean isFull() | 큐에 들어 있는 데이터 개수가 maxsize 인지 확인 해서 boolean 값을 반환 |
| boolean isEmpty() | 큐에 들어 있는 데이터가 하나도 없는지 확인해서 boolean 값을 반환 | |
| void add(ItemType item) | 큐에 데이터 삽입 | |
| ItemType poll() | 큐에서 처음에 삽입한 제이터를 꺼내서 그 데이터를 반환 | |
| 상태 | int front | 큐에서 가장 마지막에 poll 한 위치를 기록 |
| int rear | 큐에서 최근에 add한 데이터의 위치를 기록 | |
| ItemType data[maxsize] | 큐의 데이터를 관리하는 배열 (최대 maxsize개의 데이터를 관리함) |
2-1. 1단계_비어있는 큐에 add() 연산
isFull() 연산으로 현재 큐가 가득 찼는지 확인하고 큐가 가득 차지 않았다면(isFull의 결과가 false) rear에 +1을 한 다음 rear가 가리키는 위치에 3을 add한다. 만약 isFull 연산의 결과값이 true라면 이미 큐가 꽉 찬 상태이기 때문에 데이터를 추가(add)하지 않는다.
2-2. 2단계_배열 기반의 원형 큐 (Circular Queue)에서 poll() 연산
poll()은 큐의 요소를 꺼내는 메서드이다. 위 상태에서 poll()을 호출하기 전에 isEmpty() 연산을 수행하여 큐가 비어 있는지 확인한다. isEmpty()는 front == rear일 때 true를 반환한다. 만약 true라면 큐가 비어 있는 것이므로 poll() 연산을 수행하지 않고 종료된다.
반면, 만약 큐가 비어 있지 않다면 (isEmpty()가 false를 반환할 경우), front 값을 증가시킨다. 원형 큐라면 (front + 1) % capacity 연산을 수행해서 순환구조가 유지된다.
그래서 배열에서 실제 데이터를 지우는 것이 아니라 front 위치만 변경하여 데이터를 삭제한 것처럼 처리한다. 따라서 만약 poll() 후 front == rear이면 큐가 비어 있음을 의미하고 isEmpty() 연산 시 true가 나온다.
원형 큐에서는 front와 rear를 순환 구조로 유지하여 배열을 효율적으로 사용한다. 반면에 원형 큐 (Circular Queue) 가 아닌 일반적인 배열 기반 큐라면, poll() 시마다 front가 증가하면서 배열 공간이 낭비될 수 있다. 이것을 방지하려면 데이터를 앞으로 당기는 추가 작업이 필요하다.
2-3. 3단계_계속해서 add() 하기
계속해서 add 한다. 5를 add하면 isFull() 연산을 수행해서 큐가 가득 찼는지 확인하고, 가득 차지 않으면 숫자를 큐에 추가한다. 6과 8을 add하고 나면 front 는 0 rear는 3이 된다.
2-4. 4단계_큐가 가득 찼을 때 add()하면 어떤 일이 일어날까?
이제 큐가 가득 찼을 때 add하면 어떻게 되는지 살펴 보자. rear가 3이기 때문에 maximize-1과 같다. isFull() 연산은 true이므로 더 이상 add()를 수행하지 못한다.
여기서 생각 해 볼 내용이 하나 있다. 마지막 add에서 실제 data에 저장한 데이터가 3, 5, 6, 8로 4개 이지만 큐는 5, 6, 8로 3개이다. 즉, 큐는 front의 다음부터 rear까지를 큐가 관리하는 데이터로 인식한다. 실제로는 data의 공간이 4개인데 큐가 관리하는 데이터는 3개이므로 실질적으로는 메모리 공간을 낭비한 상황이다. 이렇게 되는 이유는 큐를 한 방향으로 관리하고 있기 때문이다. 이렇게 하면 front 이전의 공간을 활용하지 못 한다. 즉, front 이전을 기준으로 큐가 사용할 수 있는 부분과, 사용할 수 없는 부분으로 나뉘게 된다.
2-5. 큐를 원형으로 만들기
위에서 살펴본 문제점을 개선하기 위해 고안한 다른 형태의 큐가 원형 큐이다. 위에까지의 설명은 선형큐였다. 낭비하는 공간을 없애기 위해 원형으로 큐를 만들고 front와 rear가 돌아간다. 원형 큐는 선형 큐보다 구현이 복잡하지만 메모리 공간을 절약할 수 있다는 장점이 있다. 다만 코딩테스트에서는 자바 컬렉션에서 제공하는 Queue 인터페이스까지만 알아도 충분하다. 왜냐하면 자바의 Queue는 배열의 길이를 자동으로 관리하기 때문이다. 굳이 메모리를 효율적으로 쓰기 위해 원형 큐를 사용할 필요까지는 없고 이런 게 있다 정도로 알아 두면 좋다.
3. 큐를 구현하는 2가지 방식
1. Queue 인터페이스
2. ArrayDeque 덱 클래스
3-1. Queue 인터페이스
Queue<Integer> queue = new ArrayDeque<>();Queue 인터페이스에서는 add 연산을 add()로 메서드로 수행하고 poll 연산은 poll()로 수행한다.
add 연산은 offer() 메서드로도 가능하지만 내부에서 offer() 메서드의 호출 횟수가 1회 더 많기 때문에 add() 메서드를 사용하는 것이 아주 약간의 차이로 빠를 수 있다.
그리고 자바 컬렉션 프레임워크에서 Queue는 인터페이스로 구현되어 있다. Queue의 구현체로 자주 사용하는 클래스는 ArrayDeque와 LinkedList이다. 코테에서는 일반적으로 LinkedList < ArrayDeque이다.
3-2. 덱을 큐처럼 활용하는 방법
ArrayQueue<Integer> queue = new ArrayDeque<>();덱은 Double Ended Queue의 줄임말이다. 말 그대로 양 끝에서 삽입이나 삭제를 할 수 있는 큐를 구현한 것이다. 하지만 ArrayDeque에서는 add()와 poll()보다 addLast()메서드와 pollFirst() 메서드를 대신 사용하는 것이 좋다.
위 그림에서 큐를 기준으로 왼쪽이 First, 오른쪽은 Last이다. 데이터를 왼쪽에서 꺼내는 걸 pollFirst(), 오른쪽으로 넣는 것은 addLast()이다. 추가로, 만약에 데이터를 addFirst()로만 넣고 pollFirst()로만 꺼내면 동작이 stack의 push(), pop()과 동일해서 ArrayDeque로 큐, 스택, 덱 모두 수현이 가능하다.
4. 큐의 상속관계
내가 만든 자료 외 사진 자료 출처
Deque, LinkedList 와 ArrayDeque
이번 시간에는 Deque 인터페이스를 알아보고 이의 구현체인 LinkedList와 ArrayDeque를 알아보고 비교할 것이다. 1. Deque란? 원소의 추가와 삭제를 둘 다 끝부분에서 지원하는 선형 collection. Deque라는 이
tech-monster.tistory.com
Java: 덱(Deque)의 개념과 사용
덱 Double-Ended Queue 큐의 양쪽에 데이터를 넣고 뺄 수 있는 자료구조 큐 또는 스택으로도 사용할 수 있다 덱의 분류 한 쪽으로만 입력이 가능한 덱 = Scroll 한쪽으로만 출력이 가능한 덱 = Shelf 덱은
devyoseph.tistory.com
'코딩테스트 > 알고리즘' 카테고리의 다른 글
| [코딩테스트/알고리즘 맛집] 자바 스택(Stack) 문제 유형과 코드 정리 (12) | 2025.02.19 |
|---|---|
| [알고리즘] 코딩테스트 코드 구현 노하우 - 해시맵, StringBuffer, 조기반환, 보호구문, 제네릭기법 (7) | 2025.02.16 |
| [알고리즘] 그림과 문제로 알아보는 이진트리 탐색 (이분 탐색, Binary Search) (12) | 2025.02.15 |
| [코딩테스트/알고리즘 맛집] 자바 정렬(Sort) 코딩테스트에서 자주 나오는 문제 유형과 풀이 팁 (30) | 2025.02.08 |
| [코딩테스트/알고리즘 맛집] 그리디 알고리즘 (Greedy Algorithm) 으로 빠르고 효율적으로! (18) | 2025.02.05 |