

어려워서 미루다가 못 푼 문제가 2개 있었다. Lv4 문제 1개랑 Lv5 문제 1개이다. 난이도 최상인 만큼, 문제 읽기도 전에 풀기가 두려운 마음이 있었다. 이 문제는 왠지 오랫 동안 노트북 앞에 앉아서 머리 많이 쓰고 고민해 봐야 될 것 같아서 하기싫었다. MySQL에서는 START WITH CONNECT BY가 안된다는 거 알고부터는 또 새로운거 배우기 싫어서 미뤘는데 오늘 얼른 끝내버리고 자야지
1. 문제설명

2. 접근방식
처음에는 어려워 보여서 문제를 읽고 뭘 구해야 하는지 생각의 흐름을 한글로 받아 적어 봤다.
PARENT_ID가 NULL이면 1세대이다.
PARENT_ID가 NULL인 ID를 부모로 가지는 행이 2세대 이다.
PARENT_ID가 NULL인 ID를 부모로 가지는 행의 ID를 부모로 가지는 행이 3세대 이다.
여기까지 받아 적으니까 계층쿼리인데
START WITH PARENT_ID IS NULL 로 시작하고 LV이 3인 ID만 조회하면 되겠다는 생각이 떠올랐다!
처음에는 이걸 하나 하나 따라가면서 계산해줘야 한다는 생각에
쿼리도 길어질 것 같고 오래걸릴 거 같다 생각했는데
설마 이렇게 쉽게 풀린다고??
SELECT ID
FROM ECOLI_DATA
START WITH PARENT_ID IS NULL
CONNECT BY PRIOR ID = PARENT_ID
AND LEVEL = 3
ORDER BY ID;
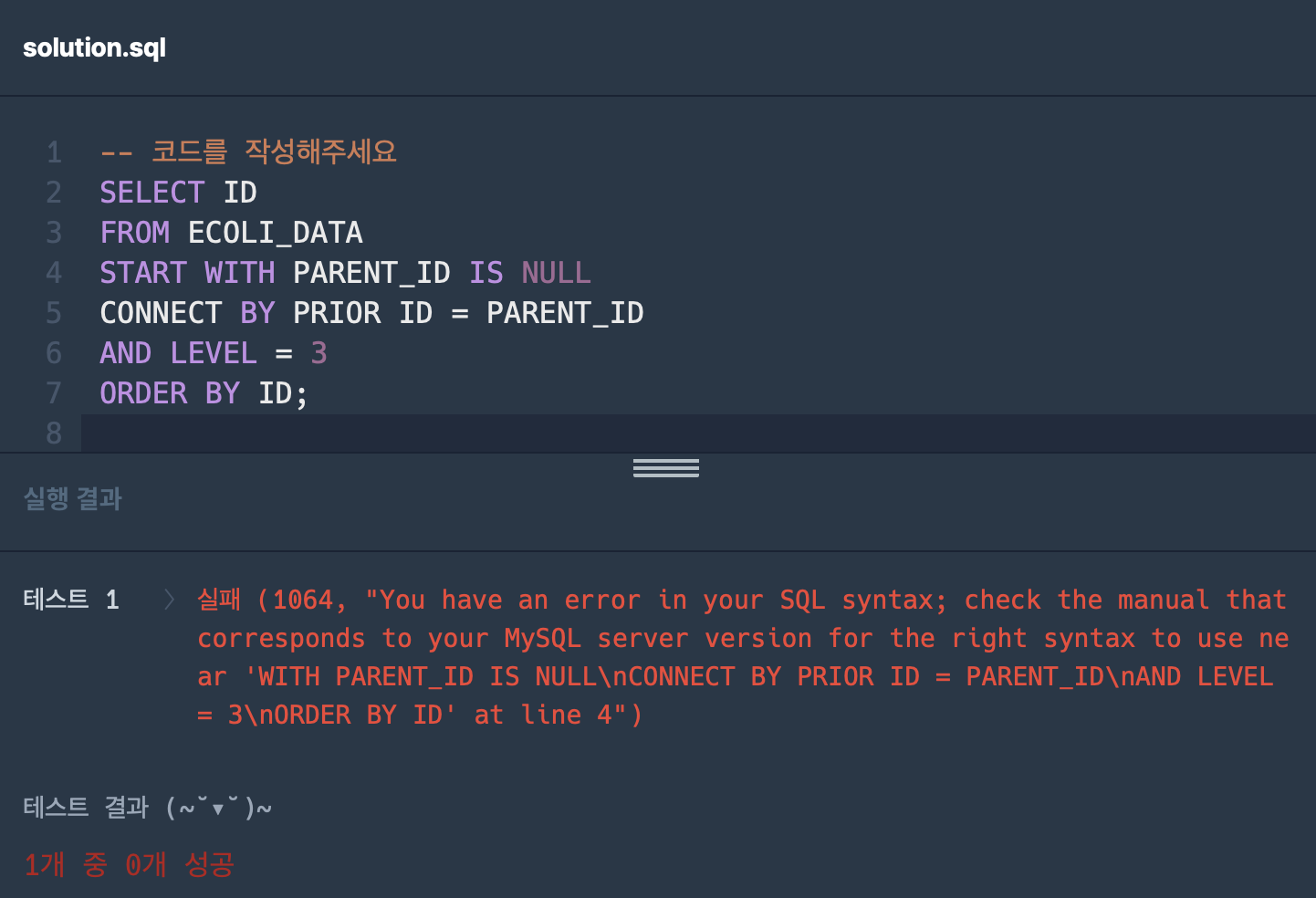
자신있게 코드를 썼으나 내가 아는 START WITH CONNECT BY는 MySQL 문법이 아니라는 Syntax Error이 뜸? 오라클에서만 되는 거구나. 그럼 이걸 다시 MySQL식으로 변환해야 한다. Oracle 로 답안 제출하는 옵션이 없어서 어쩔 수 없이 MySQL문법을 검색해 보았다. 오라클보다 코드도 훨씬 길어질 것 같지만
가보자구
⭐ WITH RECURSIVE
MySQL에서 계층쿼리를 조회하려면 `WITH RECURSIVE`라는 걸 써 줘야 한다.
조금 어려운데 WITH RECURSIVE로 재귀적 CTE를 정의해 주는 것이다.
CTE는 공동테이블 표현식이다. CTE(Common Table Expression)는 일시적인 결과 집합을 만들어 준다. 그리고, 그 결과를 쿼리의 다른 부분에서 참조할 수 있게 해주는 구조이다. 서브쿼리랑 비슷하지만 차이가 있다.
아래는 ChatGPT가 CTE와 서브쿼리를 비교 해 준 내용이다.
⭐ CTE (Common Table Expression)란?
- 쿼리 외부에서 정의되고, 쿼리 본문에서 참조된다.
- WITH 키워드를 사용하여 정의한다.
- 재사용할 수 있는 일시적인 결과 집합을 만든다.
- 한 번 정의된 후, 다양한 부분에서 참조할 수 있다.
- 재귀적 쿼리에서 자주 사용된다.
WITH CTE_NAME AS (
SELECT column1, column2
FROM some_table
WHERE condition
)
SELECT * FROM CTE_NAME;
반면 서브쿼리는?
- 쿼리 내에서 중첩된 쿼리
- SELECT, FROM, WHERE 등의 부분에서 사용된다.
- CTE와 달리 쿼리의 일부로 포함되며, 한 번만 실행된다.
- 서브쿼리의 결과는 쿼리 본문에서 한 번만 참조된다.
SELECT column1
FROM some_table
WHERE column2 IN (
SELECT column2
FROM another_table
WHERE condition
);
여기까지 ChatGPT의 자세하고 친절한 설명이었다.
나도 이걸 읽고 많이 배웠다.
이어서
WITH RECURSIVE로 계층 구조를 만드는 원리를 간단하게 설명해 보면
먼저, PARENT_ID IS NULL인 1세대 대장균을 찾는다.(AS Generation)
SELECT ID, PARENT_ID, 1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
여기서 중요한 것은 여기에서는 WITH RECURSIVE 구문 내에서 첫번째 계층이 시작되는 지점에서 AS GENERATION이라는 별칭을 주었다는 것이다. 즉, 재귀 쿼리에서 각 대장균이 몇 번째 세대에 속하는지를 추적하기 위해 사용되는 임시 컬럼을 만들어 준 것이다.
WITH RECURSIVE 쿼리에서는 보통 첫 번째 계층에서 초기 값을 지정하고, 두 번째 계층(자식 대장균)에서 그 값을 변경하거나 증가시키는 방식으로 사용한다.
그 다음에는 Generation의 ID와 ECOLI_DATA의 PARENT_ID로 JOIN 해 준다.
Generation값에 + 1 을 해 주면 2세대, 3세대, 등 연결된 모든 세대값이 나오게 된다.
SELECT e.ID, e.PARENT_ID, g.GENERATION + 1
FROM ECOLI_DATA e
JOIN Generation g ON e.PARENT_ID = g.ID
이 두 개를 UNION ALL 해 주면 연결된 계층구조를 가진 데이터 집합이 완성된다.
WITH RECURSIVE Generation AS (
-- 첫 번째 쿼리: 부모 대장균 (첫 번째 세대) 찾기
SELECT ID, PARENT_ID, 1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
-- 두 번째 쿼리: 자식 대장균 찾기
SELECT e.ID, e.PARENT_ID, g.GENERATION + 1
FROM ECOLI_DATA e
JOIN Generation g ON e.PARENT_ID = g.ID
)
WITH RECURSIVE 쿼리는 부모와 자식 관계를 재귀적으로 추적하기 때문에 각 세대를 쿼리하면서 자식이 더 이상 없으면 알아서 종료가 되는 구조이다. 즉, 자식 대장균이 더 이상 없거나 부모 대장균의 연결이 끊어지면 쿼리가 종료된다. 만약에, 어떤 대장균이 5세대에서 끝난다면 최종 세대인 5세대까지 출력을 하는 것이다.
이제 여기서 특정 계층을 조회하는 일만 남았다.
처음에 1세대 옆에 주었던 ALIAS를 ORACLE에서의 LEVEL 처럼 사용한다.
예를 들어서, 3세대 데이터만 필터링 하고 싶으면
`GENERATION = 3`이라는 조건을 준다.
3. 정답코드
WITH RECURSIVE Generation AS (
-- 첫 번째 쿼리: 부모 대장균 (첫 번째 세대) 찾기
SELECT ID, PARENT_ID, 1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
-- 두 번째 쿼리: 자식 대장균 찾기
SELECT e.ID, e.PARENT_ID, g.GENERATION + 1
FROM ECOLI_DATA e
JOIN Generation g ON e.PARENT_ID = g.ID
)
-- 세 번째 쿼리: 3세대인 데이터 조회하기
SELECT ID
FROM Generation
WHERE GENERATION = 3
ORDER BY ID;
`WITH RECURSIVE Generation AS (...)`
재귀적 CTE(Common Table Expression)를 정의
첫 번째 부분은 1세대 대장균을 찾기
`PARENT_ID IS NULL`로 최초 대장균을 선택하기
두 번째 부분은 자식 대장균 찾기
`e.PARENT_ID = g.ID`로 부모 대장균과 자식 대장균을 연결하고, `GENERATION + 1`을 사용하여 자식이 더 이상 없을 때까지 세대 찾기.
`SELECT ID FROM Generation WHERE GENERATION = 3`
GENERATION = 3을 조건으로 하여 3세대 대장균만 필터링
`ORDER BY ID`
ID 기준으로 오름차순 정렬하여 결과를 반환
🐦TMI
나는 블로그/프로그래머스에는 귀찮아서 쿼리를 모두 대문자로 작성 한다. 하지만....
많은 SQL 작성 스타일 가이드에서 테이블 및 컬럼 이름을 소문자로 작성하는 것을 권장한다.
예약어는 대문자로 쓰고 SQL 쿼리에서 컬럼 이름이나, 테이블명을 소문자로 써 주면 좋다.
소문자는 대문자로 된 코드에서 눈에도 잘 들어 오고 더 읽기 쉽고 깔끔하게 보인다.
일할때는 회사 프로젝트나 DB별로 방침이나 권장 양식이 있겠지만 그냥 혼코딩 할 때는
SQL 예약어는 대문자
테이블명과 컬럼명은 보통 소문자
사용자 정의 이름 (예: CTE명) 등 은 보통 첫 글자만 대문자
이렇게 하는 습관을 들이면 깔끔하다.
여기까지 포스팅 하느라 너무 힘들었고 위키백과 집필하는 기분이다.
와.... 문제풀고 포스팅 자료 조사 하고 설명하는데 2시간 순삭
앞으로는 5단계 문제 1개만 더 포스팅하고 SQL은 당분간 쉬어야겠다.
'코딩테스트 > SQL테스트' 카테고리의 다른 글
| [프로그래머스] (MySQL) 조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기 문제풀이 (64) | 2024.11.25 |
|---|---|
| [프로그래머스] (MySQL) ⭐⭐⭐ 멸종위기의 대장균 찾기 💯 (54) | 2024.11.21 |
| [프로그래머스] 👩🏻💻 (MySQL) 오프라인/온라인 판매 데이터 통합하기 문제 풀이 (5) | 2024.11.21 |
| [프로그래머스] 👩🏻💻 (MySQL) 대장균의 크기에 따라 분류하기 1, 2 문제 풀이 (45) | 2024.11.20 |
| [프로그래머스] 👩🏻💻 (MySQL) 대장균들의 자식의 수 구하기 문제 풀이 (44) | 2024.11.20 |