

❤️ 문제설명
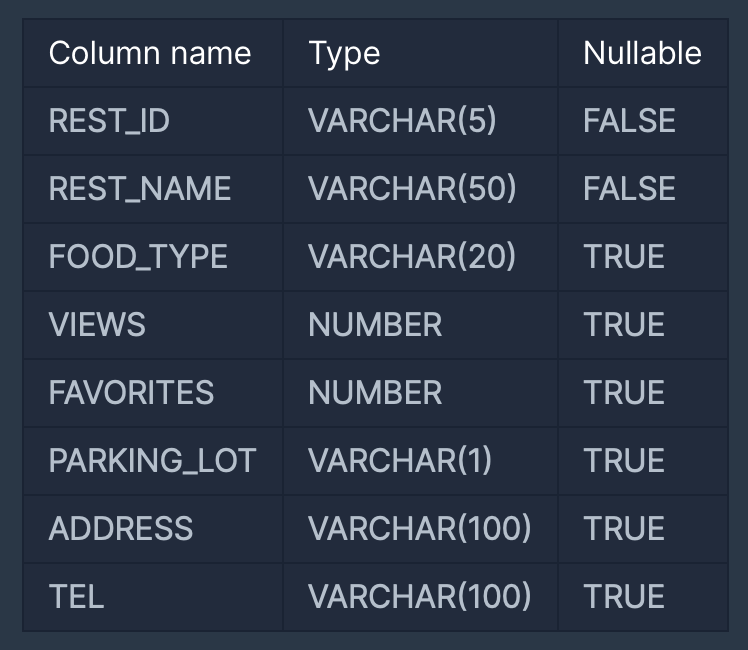
다음은 식당의 정보를 담은 REST_INFO 테이블과 식당의 리뷰 정보를 담은 REST_REVIEW 테이블입니다. REST_INFO 테이블은 다음과 같으며 REST_ID, REST_NAME, FOOD_TYPE, VIEWS, FAVORITES, PARKING_LOT, ADDRESS, TEL은 식당 ID, 식당 이름, 음식 종류, 조회수, 즐겨찾기수, 주차장 유무, 주소, 전화번호를 의미합니다.
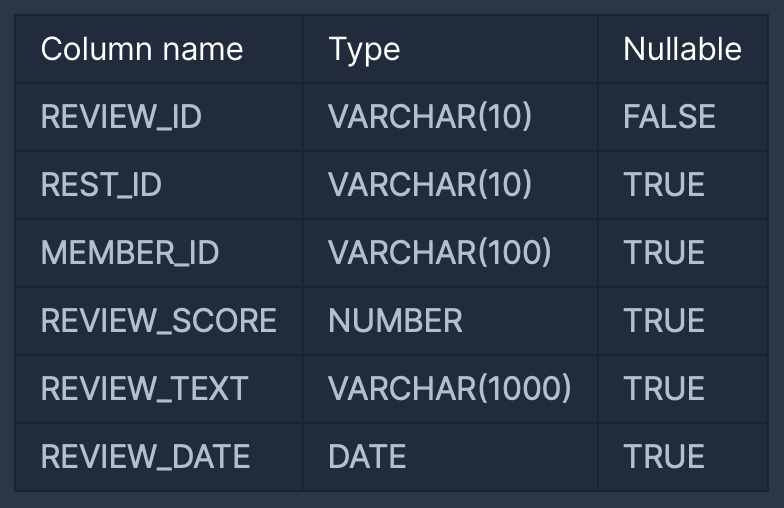
REST_REVIEW 테이블은 다음과 같으며 REVIEW_ID, REST_ID, MEMBER_ID, REVIEW_SCORE, REVIEW_TEXT,REVIEW_DATE는 각각 리뷰 ID, 식당 ID, 회원 ID, 점수, 리뷰 텍스트, 리뷰 작성일을 의미합니다.
💛 문제
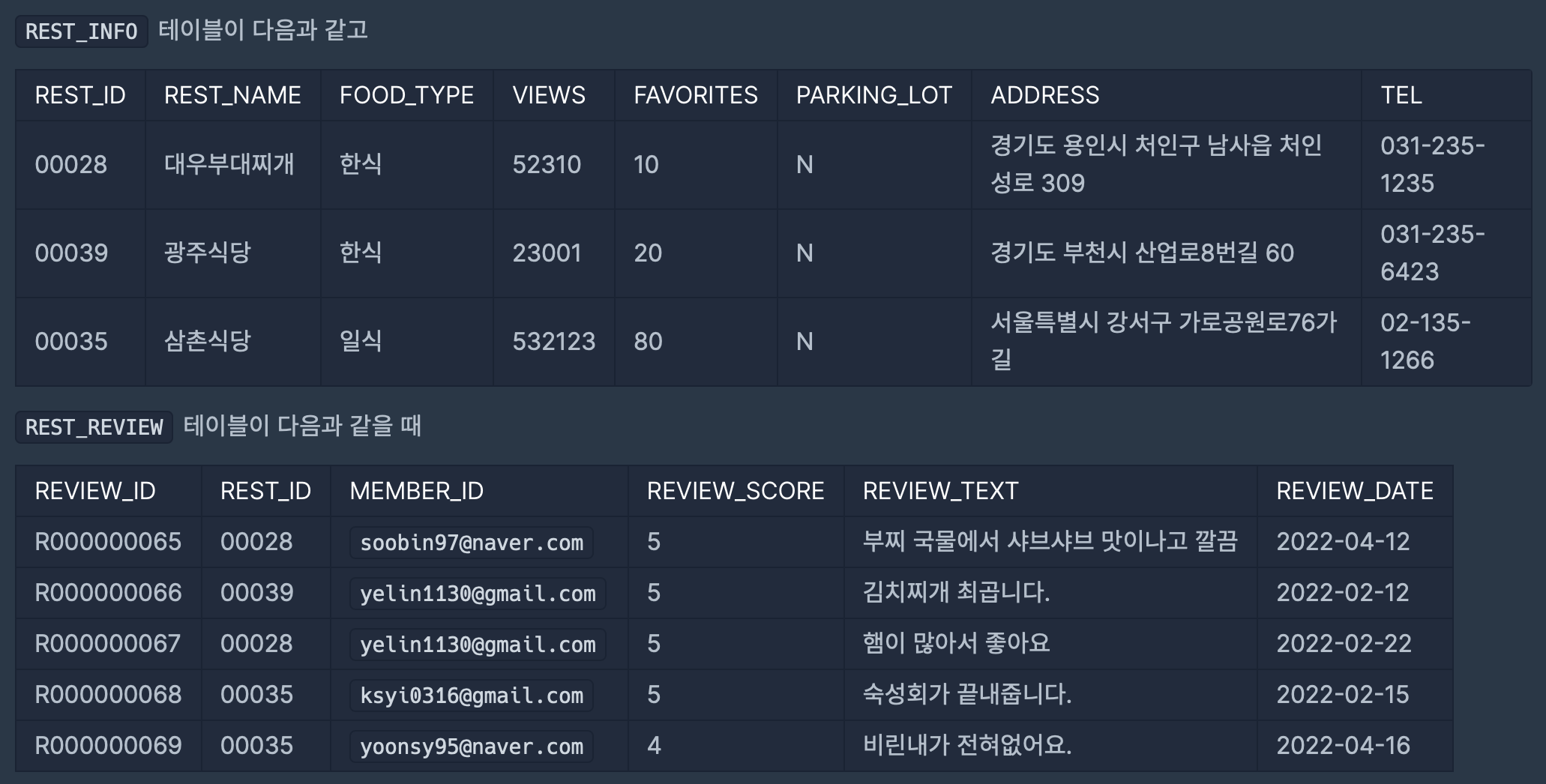
REST_INFO와 REST_REVIEW 테이블에서 서울에 위치한 식당들의 식당 ID, 식당 이름, 음식 종류, 즐겨찾기수, 주소, 리뷰 평균 점수를 조회하는 SQL문을 작성해주세요. 이때 리뷰 평균점수는 소수점 세 번째 자리에서 반올림 해주시고 결과는 평균점수를 기준으로 내림차순 정렬해주시고, 평균점수가 같다면 즐겨찾기수를 기준으로 내림차순 정렬해주세요.
💚 출력 예시

💜 풀이
첫번째 시도 🙅🏻♀️ - 틀림
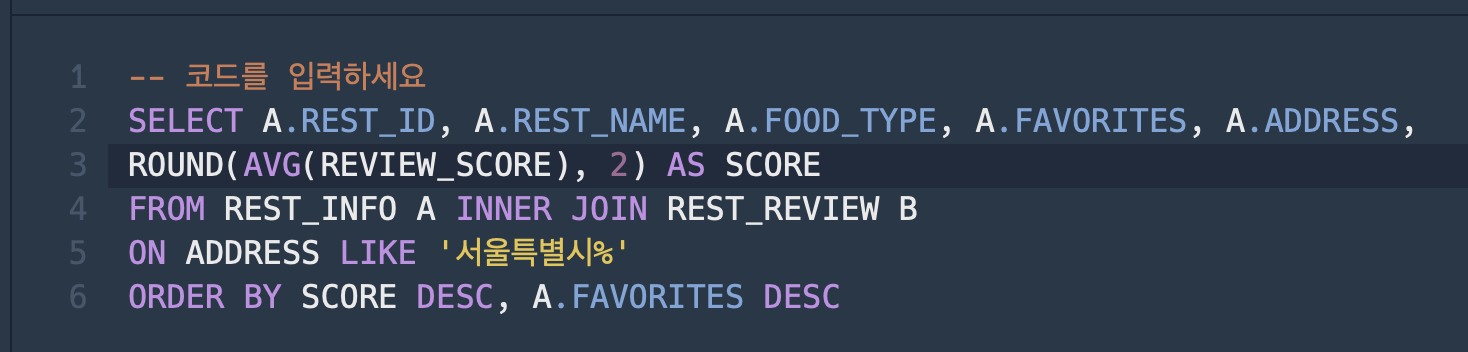
- 주소가 서울특별시인 컬럼만 조인하니까 INNER JOIN 함.
- 그리고 ADDRESS에 '서울특별시%'로 시작하는 컬럼을 조회
- B.REVIEW_SCORE에 평균을 내고, 그 값을 ROUND(COLUMN, DECIMAL PLACES)로 묶어 소수점 2째짜리까지 반올림
- 위 값에 ALIAS을 줘서 SCORE 이라고 명명

두번째 시도 🙅🏻♀️ - 틀림
일단 첫번째 시도에서 잘못된 부분을 고침.
✅ON 절에는 JOIN 조건으로 A.REST_ID와 B.REST_ID가 같다는 쿼리를 써 줘야 하고
대신 주소가 서울특별시라는 조건은 WHERE 절에 들어가야 함.
(위에서는 WHERE 절에 들어갈 조건이 ON 절에 들어가 있음)
✅AVG(REVIEW_SCORE) => AVG(B.REVIEW_SCORE)
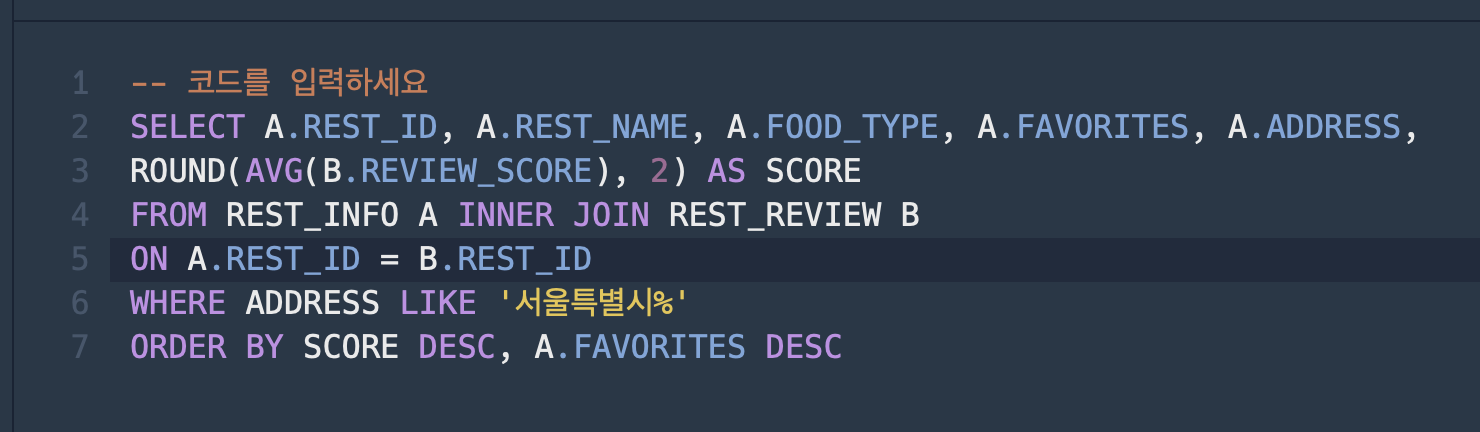
틀린 이유를 알았다! REST_REIVEW 테이블에서 REST_ID 별로 GROUP BY를 해 줘야 함
그리고 나서 A 테이블이랑 JOIN 해야 하는데 B 테이블을 인라인뷰(서브쿼리)로 만들어서 REST_ID별 집계를 먼저 해야 함
그리고 B의 REST_ID별 평균 REVIEW_SCORE를 계산한 후, 이 결과를 A 테이블과 조인
세번째 시도 🙅🏻♀️ - 틀림
또 틀렸다고 합니다 ㅋㅋㅋㅋㅋ 어디가 틀린거야... 실행도 잘 되는데 ㅠㅠ
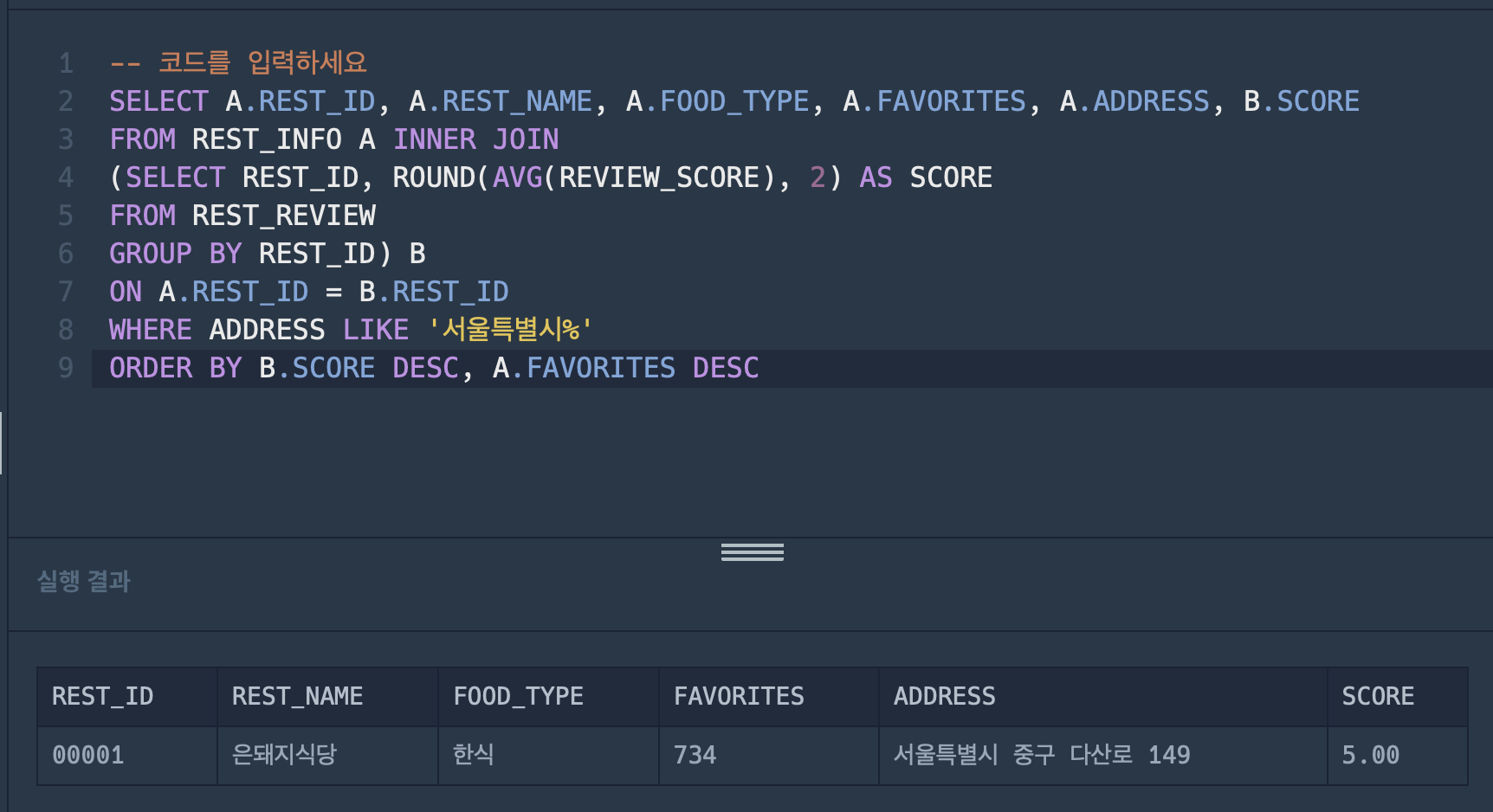
- 일단 마음에 걸리는 부분은 실행결과창 SCORE 이 5.00 이라는 것임
- 뭔가 계산이 제대로 안 된 느낌적인 느낌
도저히 모르겠움 => 결국 검색함
이 문제는 서브쿼리 써줄 필요가 없는 문제이며, GROUP BY 랑 HAVING 절을 잘 써 주면 되는 문제
네번째 시도 🙆♀️ - 정답🥳
SELECT A.REST_ID, B.REST_NAME, B.FOOD_TYPE, B.FAVORITES, B.ADDRESS, ROUND(AVG(A.REVIEW_SCORE),2) AS SCORE
FROM REST_REVIEW A
JOIN REST_INFO B ON A.REST_ID = B.REST_ID
GROUP BY A.REST_ID
HAVING B.ADDRESS LIKE '서울%'
ORDER BY SCORE DESC, B.FAVORITES DESC
SELECT A.REST_ID, A.REST_NAME, A.FOOD_TYPE, A.FAVORITES, A.ADDRESS,
ROUND(AVG(B.REVIEW_SCORE), 2) AS SCORE
FROM REST_INFO A
JOIN REST_REVIEW B ON A.REST_ID = B.REST_ID
GROUP BY A.REST_ID, A.REST_NAME, A.FOOD_TYPE, A.FAVORITES, A.ADDRESS
HAVING A.ADDRESS LIKE '서울%'
ORDER BY SCORE DESC, A.FAVORITES DESC;위에 둘 다 맞는 코드고 첫번째는 REST_REVIEW를 A로 잡았고 두번째는 REST_INFO를 A로 잡음
👇🏻 기준테이블이 A가 REST_INFO인 경우와 REST_REVIEW인 경우 GROUP BY 절에 명시해야 하는 컬럼들이 다른 이유 👇🏻
[프로그래머스] (MySQL) 서울에 위치한 식당 목록 출력하기 // 기준 테이블에 따라 GROUP BY 절에 명시
쿼리1SELECT A.REST_ID, A.REST_NAME, A.FOOD_TYPE, A.FAVORITES, A.ADDRESS, ROUND(AVG(B.REVIEW_SCORE),2) AS SCOREFROM REST_INFO A INNER JOIN REST_REVIEW B ON A.REST_ID = B.REST_IDGROUP BY B.REST_IDHAVING A.ADDRESS LIKE '서울%'ORDER BY SCORE DESC, A.FAVORI
awesomepossum.tistory.com
having절에 조건을 쓰는 경우와 where 절에 쓰는 경우 차이
✅ SQL 문의 실행 순서
FROM - WHERE - GROUP BY - HAVING SELECT - ORDER BY
SELECT department, COUNT(employee_id) AS total_employees
FROM employees
WHERE salary > 50000
GROUP BY department
HAVING COUNT(employee_id) > 5
ORDER BY total_employees DESC;위 예시 쿼리의 실행 순서는
FROM: employees 테이블을 선택
WHERE: salary > 50000 조건을 통해 직원들을 필터링
GROUP BY: 필터링된 데이터를 department 별로 그룹화
HAVING: 각 그룹의 직원 수가 5보다 많은 그룹만 선택 (집계 함수)
SELECT: department와 그룹당 직원 수를 선택
ORDER BY: 결과를 직원 수에 따라 내림차순으로 정렬
✅ WHERE 과 HAVING 절 사용 시점
WHERE
- 사용 시점: 그룹핑 전에 데이터를 필터링할 때 사용
- 적용 대상: 개별 행을 기준으로 조건을 적용
- 특징: GROUP BY 또는 집계 함수가 사용되기 전에 조건을 걸어야 할 때 유용
- 예시: WHERE age > 18처럼 그룹핑을 하기 전에 age 열에서 18보다 큰 행들만 필터링하는 경우에 사용
HAVING
- 사용 시점: 그룹핑 후 또는 집계 함수가 사용된 데이터에 조건을 적용할 때 사용
- 적용 대상: 그룹화된 결과에 대해 조건을 걸 때 유용하며, 집계 함수가 들어간 조건을 걸 때 주로 사용
- 특징: SUM, COUNT, AVG 등 집계 함수가 포함된 조건을 적용할 때 사용
- 예시: HAVING COUNT(*) > 1처럼 특정 그룹의 집계 값이 기준을 만족하는지 필터링
'Algorithm > SQL테스트' 카테고리의 다른 글
| [프로그래머스] 🐶 (MySQL) 동물의 아이디와 이름, 여러 기준으로 정렬하기 (2) | 2024.10.28 |
|---|---|
| [프로그래머스] (MySQL) 서울에 위치한 식당 목록 출력하기 // 기준 테이블에 따라 GROUP BY 절에 명시해야 하는 컬럼이 다른 이유 (4) | 2024.10.28 |
| [프로그래머스] 👩🏻💻 (MySQL) 어린 동물 찾기 (1) | 2024.10.27 |
| [프로그래머스] 👩🏻💻 (MySQL) 아픈 동물 찾기 (2) | 2024.10.27 |
| [프로그래머스] 👩🏻💻 (MySQL) 3월에 태어난 여성 회원 목록 출력하기 (2) | 2024.10.27 |
❤️ 문제설명
다음은 식당의 정보를 담은 REST_INFO 테이블과 식당의 리뷰 정보를 담은 REST_REVIEW 테이블입니다. REST_INFO 테이블은 다음과 같으며 REST_ID, REST_NAME, FOOD_TYPE, VIEWS, FAVORITES, PARKING_LOT, ADDRESS, TEL은 식당 ID, 식당 이름, 음식 종류, 조회수, 즐겨찾기수, 주차장 유무, 주소, 전화번호를 의미합니다.
REST_REVIEW 테이블은 다음과 같으며 REVIEW_ID, REST_ID, MEMBER_ID, REVIEW_SCORE, REVIEW_TEXT,REVIEW_DATE는 각각 리뷰 ID, 식당 ID, 회원 ID, 점수, 리뷰 텍스트, 리뷰 작성일을 의미합니다.
💛 문제
REST_INFO와 REST_REVIEW 테이블에서 서울에 위치한 식당들의 식당 ID, 식당 이름, 음식 종류, 즐겨찾기수, 주소, 리뷰 평균 점수를 조회하는 SQL문을 작성해주세요. 이때 리뷰 평균점수는 소수점 세 번째 자리에서 반올림 해주시고 결과는 평균점수를 기준으로 내림차순 정렬해주시고, 평균점수가 같다면 즐겨찾기수를 기준으로 내림차순 정렬해주세요.
💚 출력 예시
💜 풀이
첫번째 시도 🙅🏻♀️ - 틀림
- 주소가 서울특별시인 컬럼만 조인하니까 INNER JOIN 함.
- 그리고 ADDRESS에 '서울특별시%'로 시작하는 컬럼을 조회
- B.REVIEW_SCORE에 평균을 내고, 그 값을 ROUND(COLUMN, DECIMAL PLACES)로 묶어 소수점 2째짜리까지 반올림
- 위 값에 ALIAS을 줘서 SCORE 이라고 명명
두번째 시도 🙅🏻♀️ - 틀림
일단 첫번째 시도에서 잘못된 부분을 고침.
✅ON 절에는 JOIN 조건으로 A.REST_ID와 B.REST_ID가 같다는 쿼리를 써 줘야 하고
대신 주소가 서울특별시라는 조건은 WHERE 절에 들어가야 함.
(위에서는 WHERE 절에 들어갈 조건이 ON 절에 들어가 있음)
✅AVG(REVIEW_SCORE) => AVG(B.REVIEW_SCORE)
틀린 이유를 알았다! REST_REIVEW 테이블에서 REST_ID 별로 GROUP BY를 해 줘야 함
그리고 나서 A 테이블이랑 JOIN 해야 하는데 B 테이블을 인라인뷰(서브쿼리)로 만들어서 REST_ID별 집계를 먼저 해야 함
그리고 B의 REST_ID별 평균 REVIEW_SCORE를 계산한 후, 이 결과를 A 테이블과 조인
세번째 시도 🙅🏻♀️ - 틀림
또 틀렸다고 합니다 ㅋㅋㅋㅋㅋ 어디가 틀린거야... 실행도 잘 되는데 ㅠㅠ
- 일단 마음에 걸리는 부분은 실행결과창 SCORE 이 5.00 이라는 것임
- 뭔가 계산이 제대로 안 된 느낌적인 느낌
도저히 모르겠움 => 결국 검색함
이 문제는 서브쿼리 써줄 필요가 없는 문제이며, GROUP BY 랑 HAVING 절을 잘 써 주면 되는 문제
네번째 시도 🙆♀️ - 정답🥳
SELECT A.REST_ID, B.REST_NAME, B.FOOD_TYPE, B.FAVORITES, B.ADDRESS, ROUND(AVG(A.REVIEW_SCORE),2) AS SCORE FROM REST_REVIEW A JOIN REST_INFO B ON A.REST_ID = B.REST_ID GROUP BY A.REST_ID HAVING B.ADDRESS LIKE '서울%' ORDER BY SCORE DESC, B.FAVORITES DESC
SELECT A.REST_ID, A.REST_NAME, A.FOOD_TYPE, A.FAVORITES, A.ADDRESS, ROUND(AVG(B.REVIEW_SCORE), 2) AS SCORE FROM REST_INFO A JOIN REST_REVIEW B ON A.REST_ID = B.REST_ID GROUP BY A.REST_ID, A.REST_NAME, A.FOOD_TYPE, A.FAVORITES, A.ADDRESS HAVING A.ADDRESS LIKE '서울%' ORDER BY SCORE DESC, A.FAVORITES DESC;
위에 둘 다 맞는 코드고 첫번째는 REST_REVIEW를 A로 잡았고 두번째는 REST_INFO를 A로 잡음
👇🏻 기준테이블이 A가 REST_INFO인 경우와 REST_REVIEW인 경우 GROUP BY 절에 명시해야 하는 컬럼들이 다른 이유 👇🏻
[프로그래머스] (MySQL) 서울에 위치한 식당 목록 출력하기 // 기준 테이블에 따라 GROUP BY 절에 명시
쿼리1SELECT A.REST_ID, A.REST_NAME, A.FOOD_TYPE, A.FAVORITES, A.ADDRESS, ROUND(AVG(B.REVIEW_SCORE),2) AS SCOREFROM REST_INFO A INNER JOIN REST_REVIEW B ON A.REST_ID = B.REST_IDGROUP BY B.REST_IDHAVING A.ADDRESS LIKE '서울%'ORDER BY SCORE DESC, A.FAVORI
awesomepossum.tistory.com
having절에 조건을 쓰는 경우와 where 절에 쓰는 경우 차이
✅ SQL 문의 실행 순서
FROM - WHERE - GROUP BY - HAVING SELECT - ORDER BY
SELECT department, COUNT(employee_id) AS total_employees FROM employees WHERE salary > 50000 GROUP BY department HAVING COUNT(employee_id) > 5 ORDER BY total_employees DESC;
위 예시 쿼리의 실행 순서는
FROM: employees 테이블을 선택
WHERE: salary > 50000 조건을 통해 직원들을 필터링
GROUP BY: 필터링된 데이터를 department 별로 그룹화
HAVING: 각 그룹의 직원 수가 5보다 많은 그룹만 선택 (집계 함수)
SELECT: department와 그룹당 직원 수를 선택
ORDER BY: 결과를 직원 수에 따라 내림차순으로 정렬
✅ WHERE 과 HAVING 절 사용 시점
WHERE
- 사용 시점: 그룹핑 전에 데이터를 필터링할 때 사용
- 적용 대상: 개별 행을 기준으로 조건을 적용
- 특징: GROUP BY 또는 집계 함수가 사용되기 전에 조건을 걸어야 할 때 유용
- 예시: WHERE age > 18처럼 그룹핑을 하기 전에 age 열에서 18보다 큰 행들만 필터링하는 경우에 사용
HAVING
- 사용 시점: 그룹핑 후 또는 집계 함수가 사용된 데이터에 조건을 적용할 때 사용
- 적용 대상: 그룹화된 결과에 대해 조건을 걸 때 유용하며, 집계 함수가 들어간 조건을 걸 때 주로 사용
- 특징: SUM, COUNT, AVG 등 집계 함수가 포함된 조건을 적용할 때 사용
- 예시: HAVING COUNT(*) > 1처럼 특정 그룹의 집계 값이 기준을 만족하는지 필터링
'Algorithm > SQL테스트' 카테고리의 다른 글
| [프로그래머스] 🐶 (MySQL) 동물의 아이디와 이름, 여러 기준으로 정렬하기 (2) | 2024.10.28 |
|---|---|
| [프로그래머스] (MySQL) 서울에 위치한 식당 목록 출력하기 // 기준 테이블에 따라 GROUP BY 절에 명시해야 하는 컬럼이 다른 이유 (4) | 2024.10.28 |
| [프로그래머스] 👩🏻💻 (MySQL) 어린 동물 찾기 (1) | 2024.10.27 |
| [프로그래머스] 👩🏻💻 (MySQL) 아픈 동물 찾기 (2) | 2024.10.27 |
| [프로그래머스] 👩🏻💻 (MySQL) 3월에 태어난 여성 회원 목록 출력하기 (2) | 2024.10.27 |